



IT Root Cause Analysis tool: Knowledge Discovery Engine (KDE)
Dependency-aware root cause and blast radius reasoning grounded in live relationship structure.
KDE is part of Actionable Observability and runs on the AIM foundation.
Start with AIM to build your asset and dependency model. Then add Actionable Observability to unlock KDE reasoning.
AIM has a free trial. Actionable Observability does not.
KDE evaluation requires Actionable Observability enabled on top of AIM.
What You Can Validate with KDE Enabled
Estimated time: 60–90 minutes in a live environment.


When Actionable Observability is enabled, KDE allows you to confirm that it can:
- Identify one initiating cause behind related symptoms
- Separate upstream cause from downstream effects
- Show which downstream services are actually affected
- Display the dependency path behind each conclusion
- Update conclusions as infrastructure changes
Grouping follows dependency paths, not just time proximity. It is reasoning grounded in dependency structure.
What KDE Does
The Knowledge Discovery Engine is the reasoning layer inside Actionable Observability.
It answers four operational questions:
- What changed?
- What failed first?
- What does it affect?
- What should we do next?
It does this by traversing the WanAware Relationship Graph:
- Upstream to isolate the initiating cause
- Downstream to calculate real service impact
Every conclusion is backed by the dependency path used to reach it.
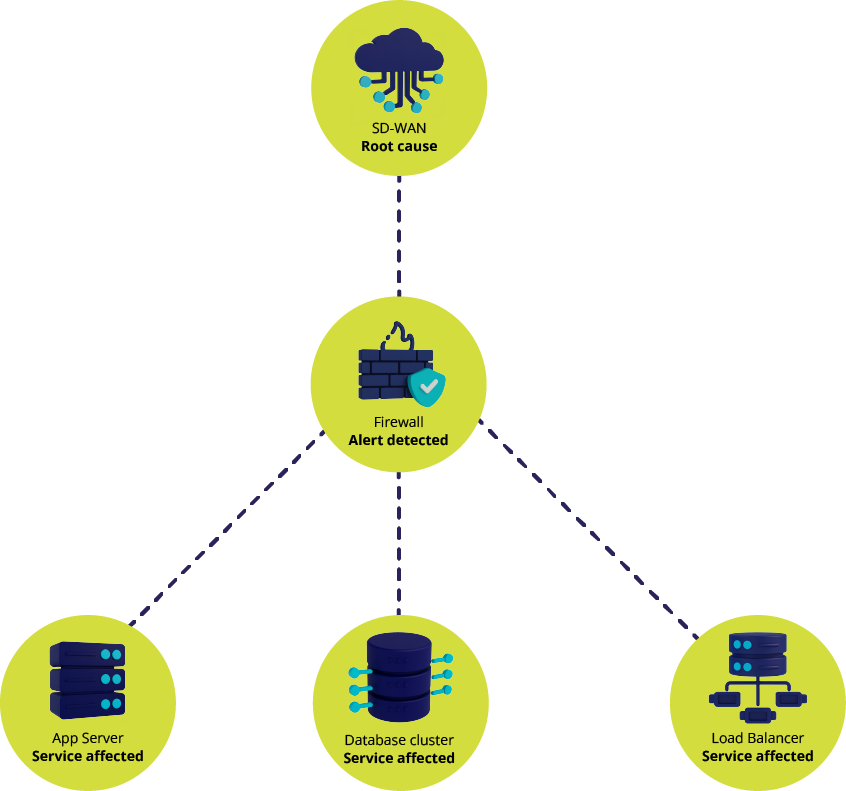

What KDE Does
- Classifies assets and signals so analysis starts in the right context
- Learns normal behavior using adaptive baselines
- Detects anomalies and drift
- Groups related symptoms under a single initiating cause
- Calculates scope and impact across dependencies
- Suggests next steps based on impact and risk, with explainable reasoning
When evidence is incomplete, KDE surfaces uncertainty instead of guessing.
Instead of asking operators to interpret alert floods manually, KDE shows where the issue started and what it touches.
How KDE Works

Inputs
 Metrics, logs, traces, and flow data
Metrics, logs, traces, and flow data- Cloud, SaaS, and orchestration telemetry
- Security, performance, and availability signals
- Change events such as scaling and configuration updates

Processing
- Normalizes signals to the correct assets
- Builds adaptive baselines from real behavior
- Detects abnormal conditions and drift
- Traverses dependency structure to isolate cause and compute impact
- Groups downstream symptoms under the initiating cause

Outputs
- Identified initiating cause
- Calculated downstream service impact
- Visible dependency path behind each conclusion
- Forward-looking risk indicators (change and dependency risk)
- Clear next-step guidance
Why This Matters in Real Operations


Incident Response
Alert storms often mask the first failure. KDE isolates the initiating cause and shows which services are truly affected.



Proactive Operations
Behavioral drift and degradation trends surface before failure cascades.


Change and Risk Management
Before approving a change, teams can evaluate likely downstream impact based on real dependency structure.

Root Cause & Blast Radius Evaluation Framework
Use our root cause and blast radius evaluation framework to validate dependency-aware reasoning in real incident conditions.
If you are evaluating KDE, focus on whether it can:
- Identify initiating cause, not just group alerts
- Separate upstream cause from downstream effects
- Calculate impact using real dependencies
- Show the dependency path behind each conclusion
- Stay accurate as infrastructure changes
Dependency-aware reasoning should hold up during messy incidents — not just clean demos.


Built on the WanAware Relationship Graph
KDE evaluates signals against the live dependency structure maintained by the Relationship Discovery Engine (RDE).
That structure:
- Stores relationships as a queryable model
- Updates as assets scale, move, or fail over
- Preserves service identity even as infrastructure shifts
- Enables fast upstream and downstream traversal
Without current dependency structure, cause and impact reasoning drifts.
If you need to verify update behavior, traversal depth, and model explainability, review the Relationship Graph Architecture Deep Dive.
Key Terms (Quick Definitions)
Dynamic baseline


Learned “normal” behavior that updates as patterns change
Anomaly
A signal that differs from expected behavior
Drift
Gradual behavioral change that may lead to failure
Initiating cause
The first failure that explains downstream symptoms
Total scope of impact
Everything affected downstream, based on dependencies
Noise suppression
Reducing alert volume by grouping symptoms under a single cause
Frequently Asked Questions
How is KDE different from traditional monitoring?
Traditional monitoring reports conditions and alerts. KDE identifies an initiating cause and calculates downstream impact using the live dependency model, with a visible dependency path behind each conclusion.
Can I trial KDE directly?
Not directly. AIM has a free trial to build your asset and dependency foundation. KDE is part of Actionable Observability, which is an add-on (no trial) enabled on top of AIM.
Does KDE rely only on static thresholds?
No. KDE learns normal operating patterns using adaptive baselines and flags anomalies and drift when behavior changes.
How does KDE reduce alert fatigue?
It groups downstream symptoms under a single initiating cause using dependency paths, so responders can focus on what started the issue and what it affects.
What should I use to evaluate KDE quickly?
Use the Evaluator Test Plan for step-by-step scenarios, and the Evaluation Checklist for consistent scoring across vendors.
Choose Your Path
New to WanAware?
Start with AIM to build your live asset and dependency foundation.KDE runs on top of this foundation.
Already Using AIM?
Learn about Actionable Observability to unlock KDE root cause and impact reasoning.
Technical evaluator?
Run the Root Cause & Blast Radius Evaluation Framework in your environment.