


Focus on Innovation, Not Outages
Go beyond the endless loop of uncertainty to one single source of truth. Turn outages from discovery into instant root-cause diagnosis, restoring service faster, and with less risk.
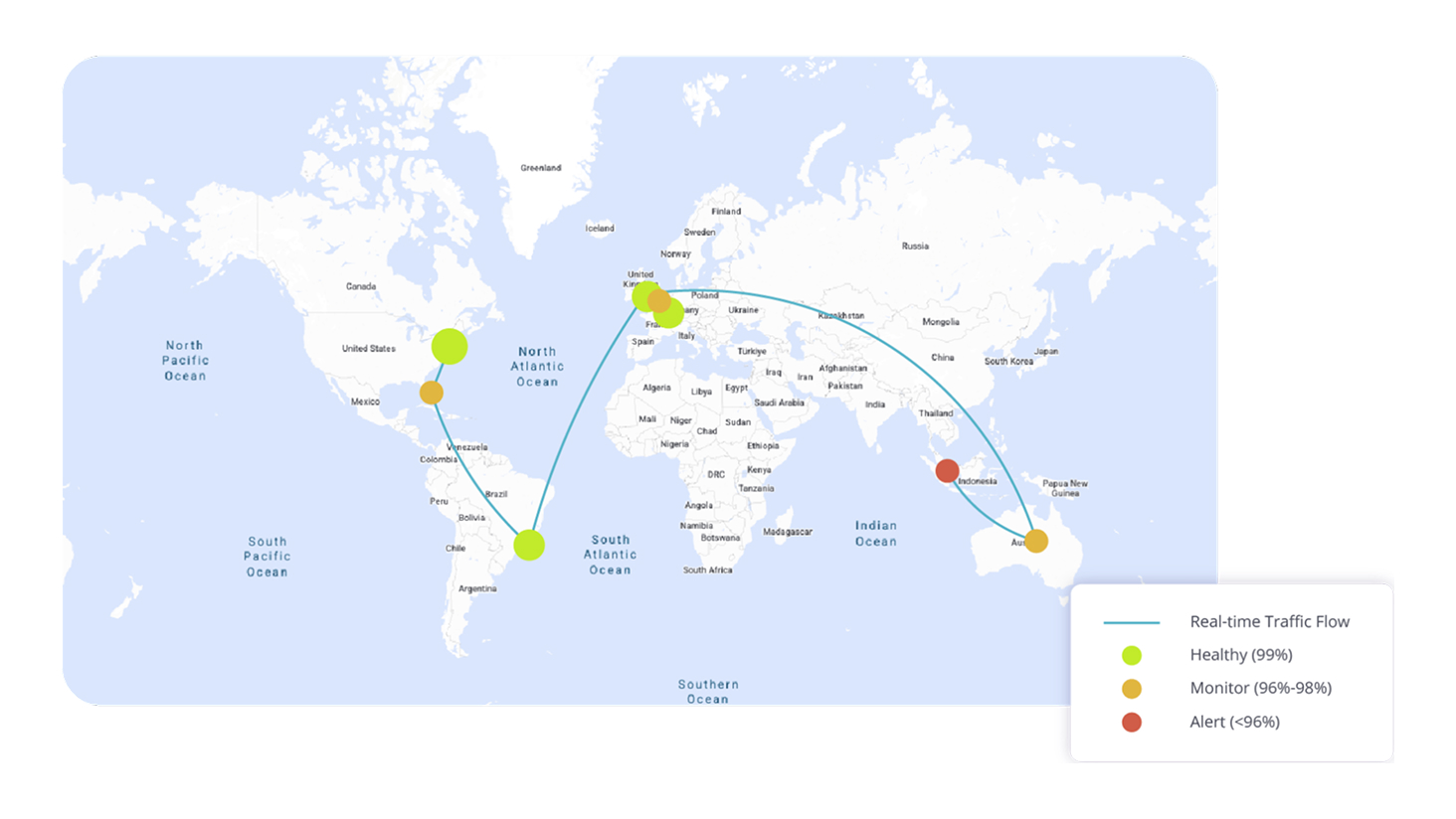

The Problem: The "Down" Dilemma
When teams say “it’s down,” they usually mean a critical business service: login, VPN access, checkout, or APIs. In modern environments, “down” is rarely a simple outage; it is a complex outage, affecting numerous downstream and upstream systems.
- Inconsistency: Success for some users, failure for others.
- Geographic Splits: One office works; others are down.
- Intermittent Failures: Retries succeed, then fail again.
- The Visibility Gap: Dashboards are green, but the application is broken.
This is the classic partial outage pattern.
Break the Loop: Trace the End-to-End Journey
In the modern stack, business services are assembled across identity providers, DNS, proxies, cloud control planes, and SaaS vendors. The path is longer, and owners are spread across different companies.
Capture the full journey of a request across network, cloud, and application layers simultaneously through a dependency and interdependency relationship graph
One unified source of truth for everyone:
- Network Team: Sees how packet loss impacts application throughput.
- App Team: Pinpoints the specific infrastructure hop adding latency.
- Cloud Team: Correlates resource allocation to end-user experience.

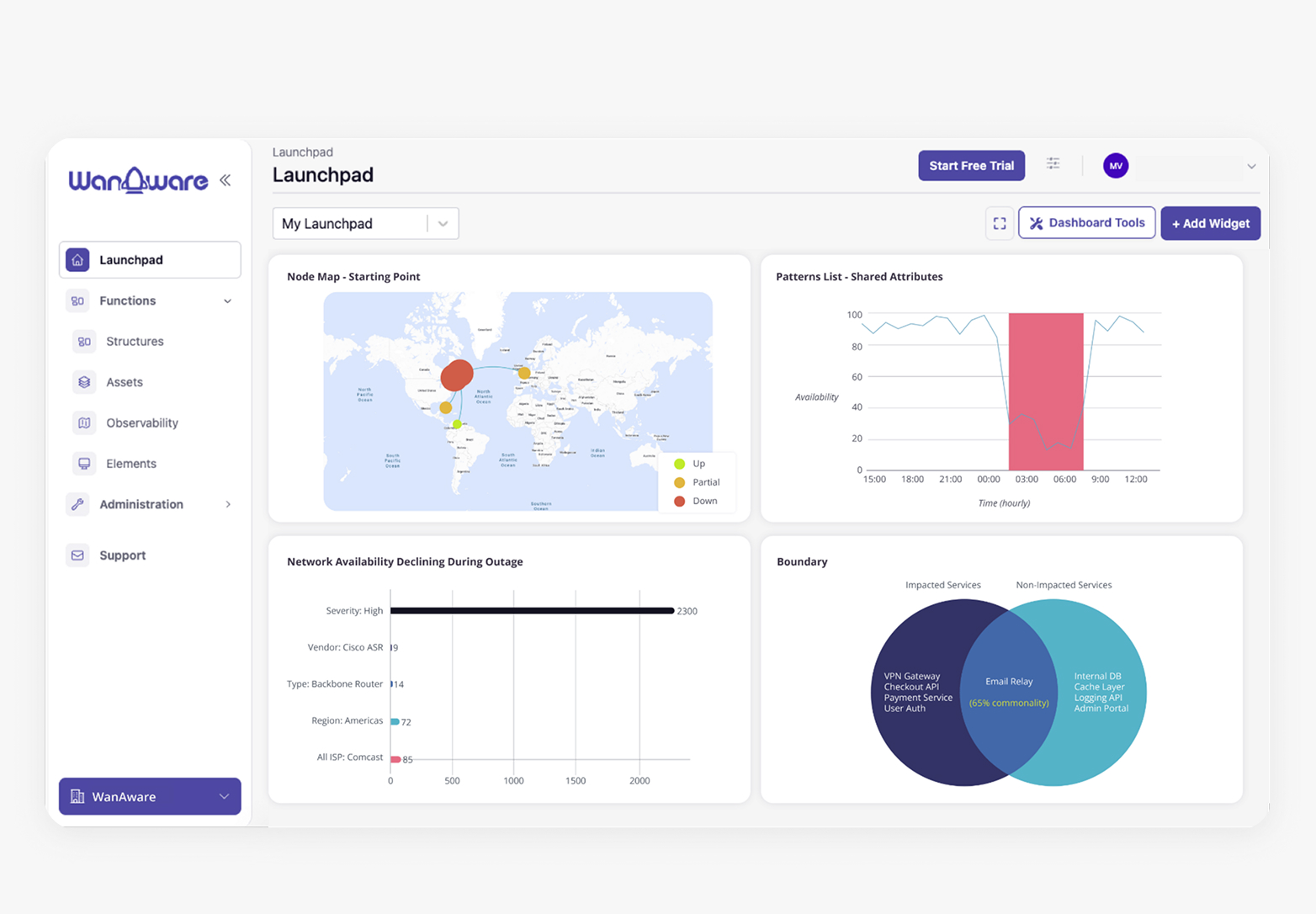
Real-Time Availability Detection & Isolation
Stop guessing if it’s "just them" or "just you." Uncover four proof points that speed ownership:
- Starting Point: The root-cause of the outage.
- Time Window: Exactly when it started, worsened, and recovered.
- Pattern: What impacted users or regions have commonality.
- Boundary of Impact: A clear definition of what is affected and what is not.
From Observation to Orchestration
Most tools only show symptoms. Leverage Actionable Observability to show you how to bypass the outage.
- Visualize — The request path behind the user experience.
- Identify — What else depends on that same failing shared system.

- Automated Remediation — Reroute traffic the moment a provider’s performance dips.
- Validate Recovery — Re-check the action end-to-end to ensure the fix worked.

Clarity Under Pressure
Close the confidence gap. When a vendor asks, "Can you show it’s on our side?", you provide the evidence. By isolating external latency from internal processing, you hand over an objective report.
.png)
The Result
Incident calls get shorter, finger-pointing stops, and performance issues are diagnosed in minutes.