



Telecom Observability at the Edge of Chaos

Telecom networks were not built for the world they now support.
Many providers still run infrastructure designed decades ago. Today, that same network has to support cloud traffic, edge computing, private 5G, and always-on services across cities and rural regions.
At the same time, customers expect service to work all the time. When it does not, they do not care why. They only feel the impact.
Telecom teams are stuck running yesterday’s systems while meeting today’s expectations. When something breaks, they often do not have a clear, current picture of what is connected. That is why outages take longer and fixes feel risky.
Why Telecom Observability Is Breaking Down
Most tools can tell you something is down. They often struggle to tell you what it affects and what to do next. That is the core telecom observability problem today.
Networks now span legacy gear, cloud platforms, and edge locations. They also change constantly. Devices come and go. Configs shift. Traffic paths reroute. Ownership is split across teams.
When teams cannot see the network as a connected system, simple questions get hard during an incident:
What failed. What does it connect to. Who owns it. What changed recently.
That missing context is why response slows down. It is also why fixes can feel like guesses.
The Real Problem Isn’t Technology
It’s What You Can’t See
In a recent telecom benchmark survey of 180 decision-makers, a pattern showed up again and again. The biggest barriers were not effort or intent. They were blind spots.
These blind spots create delays. They raise risk. They also drive up cost over time.


Blind Spot #1: You Don’t Know What You Have
Many telecom teams still rely on static inventory lists. Spreadsheets. Old databases. Records that are updated by hand.
But networks do not stand still.
New devices come online. Configurations change. Services move. Parts of the network shift to the cloud. Over time, the “source of truth” stops being true.
This hurts most during an outage. Teams cannot quickly answer:
What is this device. Where is it. What does it connect to. Who owns it.
When those basics are unclear, impact is hard to judge. Escalations multiply. Time slips away.
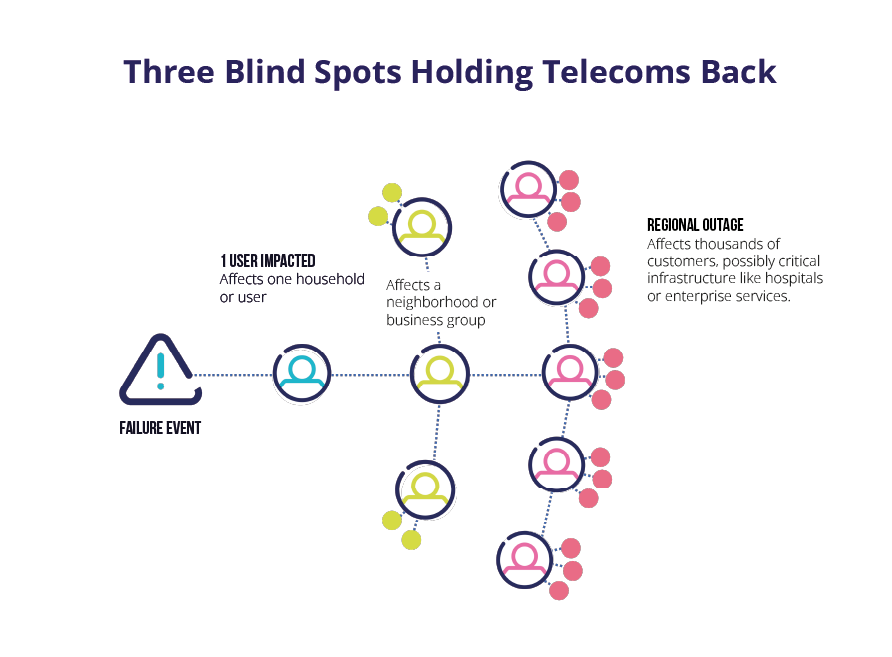
Blind Spot #2: You Don’t Know What Matters Most
Modern networks generate a flood of alerts. Many look urgent. Most are not.
A small access issue may affect one home. A failing uplink can affect a whole neighborhood. Some failures also hit business services and critical locations.
This is where blast radius matters.
Blast radius means how many people and services get hit when one thing fails. If you do not know the blast radius, you cannot rank work well.
Without impact-aware telecom observability, teams triage in the dark. They treat alerts as equal because they lack context. That leads to firefighting, missed signals, and slow recovery.
Blind Spot #3: You Don’t Know How to Fix Without Breaking Something Else
Even when teams find the issue, the fix can create a new problem.
Telecom networks have deep dependencies. One component often supports many services. A “simple” change can ripple farther than expected.
A reboot might drop more users than planned. A card swap might disconnect a bigger path. A reroute might overload another link.
Here’s the hard part: fixing fast can cause a bigger outage if you do not know what depends on that component.
That risk slows teams down. It also increases stress during every incident.
Why These Blind Spots Keep Getting Worse
These problems are not going away on their own.
Networks are expanding toward the edge. New services are added. Competition is rising. At the same time, teams are short staffed and stretched thin.
So the old approach—more dashboards, more alerts, more heroics—does not hold up.
To move forward, telecom observability has to do more than report alarms. It has to connect assets to services, show impact clearly, and help teams act with confidence.
What Comes Next
The providers that break this cycle do three things better:
- They keep an always-current view of what is in the network.
- They rank issues by impact, not by alert volume.
- They reduce the risk of fixes by understanding dependencies first.
Those changes require better visibility and better context. They also require data that stays current as the network changes.
Explore Similar Content

Explore Similar Content